
-
span class=”st0″>"^? "‘{ print $2 }’
The Cathedral and the Bazaar
Interesting podcast over at IT Conversations today featuring by Tim O’Reilly on the subject of what constitutes Open Source and the nature of freedom in Open Source. You can download or listen to the podcast here.
I enjoyed listening to Tim talk about how the nature of Open Source is changing or even needs to change with reference to Web 2.0, how Open Source isn’t just about source code or slapping an OSI license onto code anymore. It’s a fairly short talk but well worth listening to.
 For a deeper insight into the differences between the Open Source model and Commercially Written software I think everyone should read Eric Raymond’s truly excellent – The Cathedral and the Bazaar. Whilst Tim’s talk borrowed the title from Raymond’s seminal work, Tim only really briefly touches on the history of the Open Source Movement and the benefits of Open Source whilst Eric’s book and the collection of essays he presents within it provides a wealth of historical and anecdotal information that paints a wonderful picture of where and how Open Source started and why it’s been such a success.
For a deeper insight into the differences between the Open Source model and Commercially Written software I think everyone should read Eric Raymond’s truly excellent – The Cathedral and the Bazaar. Whilst Tim’s talk borrowed the title from Raymond’s seminal work, Tim only really briefly touches on the history of the Open Source Movement and the benefits of Open Source whilst Eric’s book and the collection of essays he presents within it provides a wealth of historical and anecdotal information that paints a wonderful picture of where and how Open Source started and why it’s been such a success.
I personally think anyone who considers themselves to be a software developer should read this book, not necessarily to advocate Open Source but to better understand one of the most important movements in the history of our industry.
Evolution of PHP
Came across this excellent little interview with Rasmus Lerdorf, the creator of the PHP programming language. What’s interesting is hearing him describe how PHP has evolved from being a purely procedural language to its current state of a full-fledged object oriented language..
For convenience, you can download the .mp3 of the interview here.
SVN Time Lapse View
Came across a very useful Subversion utility today. SVNTimeLapseView downloads every revision of a file from your subversion repository and allows you to scroll through the revisions using a simple slider control. As you scroll through revisions it highlights the changes that were made in each revision in blue. I found it very useful earlier today when trying to figure out what had changed in a .php file when trying to understand changes made to the file by another developer. It’s a simple but very useful tool!!
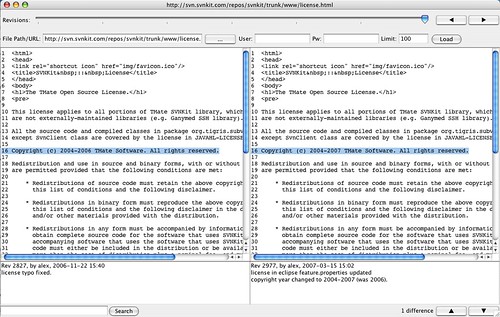
SVNTimeLapseView is free and works on any platform that runs Java, you can download it from here.
Holding a Program in One’s Head
from an excellent new essay by Paul Graham …
Good programmers manage to get a lot done anyway. But often it requires practically an act of rebellion against the organizations that employ them. Perhaps it will help to understand that the way programmers behave is driven by the demands of the work they do. It’s not because they’re irresponsible that they work in long binges during which they blow off all other obligations, plunge straight into programming instead of writing specs first, and rewrite code that already works. It’s not because they’re unfriendly that they prefer to work alone, or growl at people who pop their head in the door to say hello. This apparently random collection of annoying habits has a single explanation: the power of holding a program in one’s head.
Whether or not understanding this can help large organizations, it can certainly help their competitors. The weakest point in big companies is that they don’t let individual programmers do great work. So if you’re a little startup, this is the place to attack them. Take on the kind of problems that have to be solved in one big brain.
so very true … !
Best practises in JavaScript library design
This is a very useful tech talk by John Resig, that explores a number of techniques used to build robust, reusable cross-platform JavaScript libraries.
John offers some excellent advise and whilst some if it might seem obvious it’s worrying how many existing API’s fall into some of the common pitfalls he describes.
John argues that part of writing good solid API’s is to keep the code orthogonal by ensuring that whenever you perform an action on an object that action should be consistent across all objects. In other words each object should expose the same methods, i.e. add(), remove(), all(), … etc. this creates familiarity and developers using the API know that different objects that are responsible for different things can all be used consistently.
John also makes the obvious and profound point that when creating an API you should Fear adding methods, the reason being that every method that you write is one that you will have to maintain. In fact you should try to embrace the idea that removing unused code is a good thing. It reduces the size of your API, makes it easier to learn and easier to maintain.
Going back to consistency its imperative that we use good naming conventions and naming schemes and stick with them, this also means you have to be very diligent about argument position in method calls … I know how frustrating it is when you use some of the string processing methods in PHP but the argument order changes it’s annoying!
John goes onto offer much more advice on encapsulation, functional programming, compression of libraries using Dojo. He advocates Test Driven Development for API design which generally results in better API design.
It’s an excellent talk and well worth watching for anyone who working on building JavaScript, or indeed any kind of API.
Automated regression testing and CI with Selenium PHP
I’ve been doing some work this iteration on getting Selenium RC integrated into our build process so we can run a suite of automated functional regression tests against our application on each build. The application I’m working on is written in PHP, normally when you use Selenium IDE to record a test script it saves it as a HTML file.
For example a simple test script that goes to Google and verifies that the text “Search:” is present on the screen and the title of the page is “iGoogle” looks like this:
-
-
<html>
-
<head>
-
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
-
<title>New Test</title>
-
</head>
-
<body>
-
<table cellpadding="1" cellspacing="1" border="1">
-
<thead>
-
<tr><td rowspan="1" colspan="3">New Test</td></tr>
-
</thead><tbody>
-
<tr>
-
<td>open</td>
-
<td>/ig?hl=en</td>
-
<td></td>
-
</tr>
-
<tr>
-
<td>verifyTextPresent</td>
-
<td>Search:</td>
-
<td></td>
-
</tr>
-
<tr>
-
<td>assertTitle</td>
-
<td>iGoogle</td>
-
<td></td>
-
</tr>
-
-
</tbody></table>
-
</body>
-
</html>
-
You can choose to export the script in several other languages, including PHP, in which case the test script it produces looks like this:
-
span class=”st0″>’Testing/Selenium.php’‘PHPUnit/Framework/TestCase.php’"*firefox", "http://localhost:4444/""/ig?hl=en""Search:""iGoogle"
The Export produces a valid PHPUnit test case that uses the Selenium PHP Client Driver(Selenium.php). Whilst the script is valid and will run you do need add a little more to it before the test will correctly report errors. As it stands all errors captured during the test are added to an array called verificationErrors, by catching the assertion Exceptions that are thrown when an assert fails, in other words if you ran this test as it is, and it did fail you wouldn’t know! To correct this we need to do two things. Firstly, each assert needs to have a message added to it which will printed out in the test report if the assert fails. Secondly we need to modify the tearDown method so that once a test has run, it checks the verificationErrors array, and if any failures have occurred, fails the test. After making these changes the PHP test script looks like this:
-
span class=”st0″>’Testing/Selenium.php’‘PHPUnit/Framework/TestCase.php’"*firefox",
-
"http://localhost:4444/""VERIFICATION ERRORS:""\n""/ig?hl=en""Search:"),
-
"The string Search: was not found""iGoogle",
-
$this->selenium->getTitle(),
-
"The page title did not match iGoogle."
Obviously, I have also given the PHP Class and test function slightly more meaningful names. Now you have a PHP Unit Test case that will use the Selenium PHP Client Driver with Selenium Remote Control to launch a browser, go to the specified URL, and test a couple of assertions. If any of those assertions fail, the tearDown method fails the test … pretty cool, right?
Well now it get’s better. Because the Selenium Client Driver has a published api which is pretty easy to follow, there’s no reason why you can’t just write test cases without using Selenium IDE … for those who want to you could even incorporate this into a TDD process. But for all this to hang together we need to be able to run a build, on a Continuous Integration server which checks out the code, runs unit tests and selenium regression tests against that code line, and only if all tests succeed passes the build.
We are currently using ANT, and CruiseControl to handle our CI/Automated build process. When running the automated suite of tests we need to ensure that the Selenium Remote Control server is also running which creates some complications. The Selenium Remote Control server takes several arguments which can also include the location of a test suite of html based selenium tests – which is really nice because the server will start, execute those tests and then end. Unfortunately you can’t invoke the server and pass it the location of a PHP based test suite. This means you need to find a way to start up the server, then run your tests, and once they are complete, shut the selenium server down.
He are the ANT targets that I have written to achieve this, if anyone can think of better ways of doing this I’d welcome any feedback or suggestions, to run this example you’d simply enter the command “ant selenium” :
-
-
<target name="selenium" depends="clean, init" description="Run the Selenium tests">
-
<parallel>
-
<antcall target="StartRCServer" />
-
<antcall target="RunSeleniumTests" />
-
</parallel>
-
</target>
-
-
<target name="StartRCServer" description="Start the Selenium RC server">
-
<java jar="dependencies/SeleniumRC/lib/selenium-server.jar"
-
fork="true" failonerror="true">
-
<jvmarg value="-Dhttp.proxyHost=host.domain.com"/>
-
<jvmarg value="-Dhttp.proxyPort=80"/>
-
</java>
-
</target>
-
-
<target name="RunSeleniumTests" description="RunAllSeleniumTests">
-
<sleep milliseconds="2000" />
-
<echo message="======================================" />
-
<echo message="Running Selenium Regression Test Suite" />
-
<echo message="======================================" />
-
<exec executable="php"
-
failonerror="false"
-
dir="test/seleniumtests/regressiontests/"
-
resultproperty="regError">
-
<arg line="../../../dependencies/PHPUnit/TextUI/Command.php –log-xml ../../../doc/SeleniumTestReports/RegressionTests/TestReport.xml AllRegressionTests" />
-
</exec>
-
<get taskname="selenium-shutdown"
-
src="http://localhost:4444/selenium-server/driver/?cmd=shutDown"
-
dest="result.txt" ignoreerrors="true" />
-
-
<condition property="regressionTest.err">
-
<or>
-
<equals arg1="1" arg2="${regError}" />
-
<equals arg1="2" arg2="${regError}" />
-
</or>
-
</condition>
-
-
<fail if="regressionTest.err" message="ERROR: Selenium Regression Tests Failed" />
-
</target>
-
A couple of notes, the reason I have to use a conditional check at the end of the selenium target is because, if the exec task that runs the PHP tests was set to failonerror=true then the build would never reach the next line which shuts the Selenium RC server down. To ensure that always happens I have to set the exec to failonerror=false, but this means I have to check what the result was from the exec. Which if successful will return 0, if test failures exist will return 1, and if there were any errors (preventing a test to be exectuted ) will return 2. Hence the conditional check sets regressionTest.err if either of these latter two conditions are true.
Also in order to start up the server, which could take up to a second, but can’t be sure precisely how long. I have to use the Ant Parallel task, which calls the task to start the server and the task to run the tests at the same time. The task to run the tests has a 2 second sleep in it, which should be more than enough time to allow the server to start. This all kind of feels a little clunky, but at the moment it does work very well.
In a nutshell, thats how you integrate PHP based Automated Selenium Regression tests into a continuous build.
-
Interesting PHP / XSL Cross Platform Defect
Came across a rather interesting cross platform problem whilst trying to perform a rather simple xsl transformation using PHP. To understand the problem take a look at this little snippet of XSL and see if you can spot what’s wrong with it:
-
-
<xsl:template name="someTemplate">
-
<xsl:for-each select="/rdf:RDF/rss:item" >
-
<xsl:param name="foo"/>
-
…
-
</xsl:for-each>
-
</xsl:template>
-
The flaw in the snippet above is that it defines an xsl:param inside an xsl:for-each which is completely invalid. Now earlier today one of my colleagues was refactoring some XSL and whilst he was copying code from one template into another he inadvertently made the mistake above. Now you’d like to think that when you try to run the XSL through PHP that the invalid markup would throw an error. Well under PHP 5.2.2 on Window’s it doesn’t throw an error – in fact the XSL runs and performs the transformation. However when you run the same XSL under PHP running on Linux it quite rightly throws an error and informs you that the xsl:param is invalid.
I haven’t looked too deeply into why the invalid markup is accepted under Windows, I suspect it might have something to do with the php_xsl.dll that is comes as part of PHP 5.2.2, but it is something that made my jaw drop. Has anyone else experienced this?
Some more useful Firefox extensions
Been using several very useful Firefox extensions that have made my life considerably easier lately.
The first is called Duplicate Tab, which allows you to create a new tab that duplicates a currently open tab – along with all its history. I’m finding this very useful when im writing SPARQL queries against our platform where I invariably end up having lots of tab’s open because I often write a query, run it, but then want to be able to keep the results open so I can write another query but to do that I have to manually open a tab, navigate to the bookmark … and thats tedious when your trying to get stuff done. Its so much nicer being able to run the query – and then duplicate the tab, hit back in the duplicated tab and now I have one tab with the results in it and one tab with the editing pane in it … away I go!
The second is the Google Preview extension. When you do a search in Google this extension inserts preview thumbnail images of websites, which I find quite useful.
The final extension is Pearl Crescent Page Saver (basic), which allows you to take a screenshot of the current page your viewing in the browser as a png.
Calling PHP Functions from XSL
Craig, a colleague of mine who newly joined our development team at Talis showed me this neat little trick. Many things are far easier to do in PHP than they are in XSL, and some things simply can’t be done in pure XSL. A solution is to call PHP functions directly from within your XSL.
1) In your xsl stylesheet add:
namespace xmlns:php="http://php.net/xsl" exclude-result-prefixes="php"
2) To call the php function and access the result use:
-
-
<!– for string use this –>
-
<xsl:value-of select="php:functionString(‘phpFunctionName’, /xpath)"/>
-
-
<!– for DOM Nodes use this –>
-
<xsl:copy-of select="php:function(‘phpFunctionName’, /xpath)"/>
-
You can pass as many parameters as you want to either php:function or php:functionString – the latter merely converts output to a string and otherwise they are identical.
3) you must register them with the XSL Transformer:
-
span class=”co1″>// This is the important call for this functionality
4) In your php function, access parameters passed in as strings as if they are a php string. If you pass a dom structure as a parameter then you need to access it along the lines of:
-
span class=”st0″>’namespace’, ‘element-name’
$DomList will include the root element of the XPath used to call the PHP function
If you want to dump what you pass to PHP as a string you need to do:
-
span class=”co1″>// note this function isn’t yet documented in the PHP manual !
-
}
-
It’s a very useful feature … good luck with it.
-
-